
前排感谢这个开源项目:https://github.com/Morizeyao/GPT2-Chinese
记录下运行以上项目的流程。
运行环境

导入语料
由于使用单一文本进行训练,只需要把数据集放置在./data/train.json即可。

如果需要合并txt文本,使用批处理type *.txt>>all.txt即可。
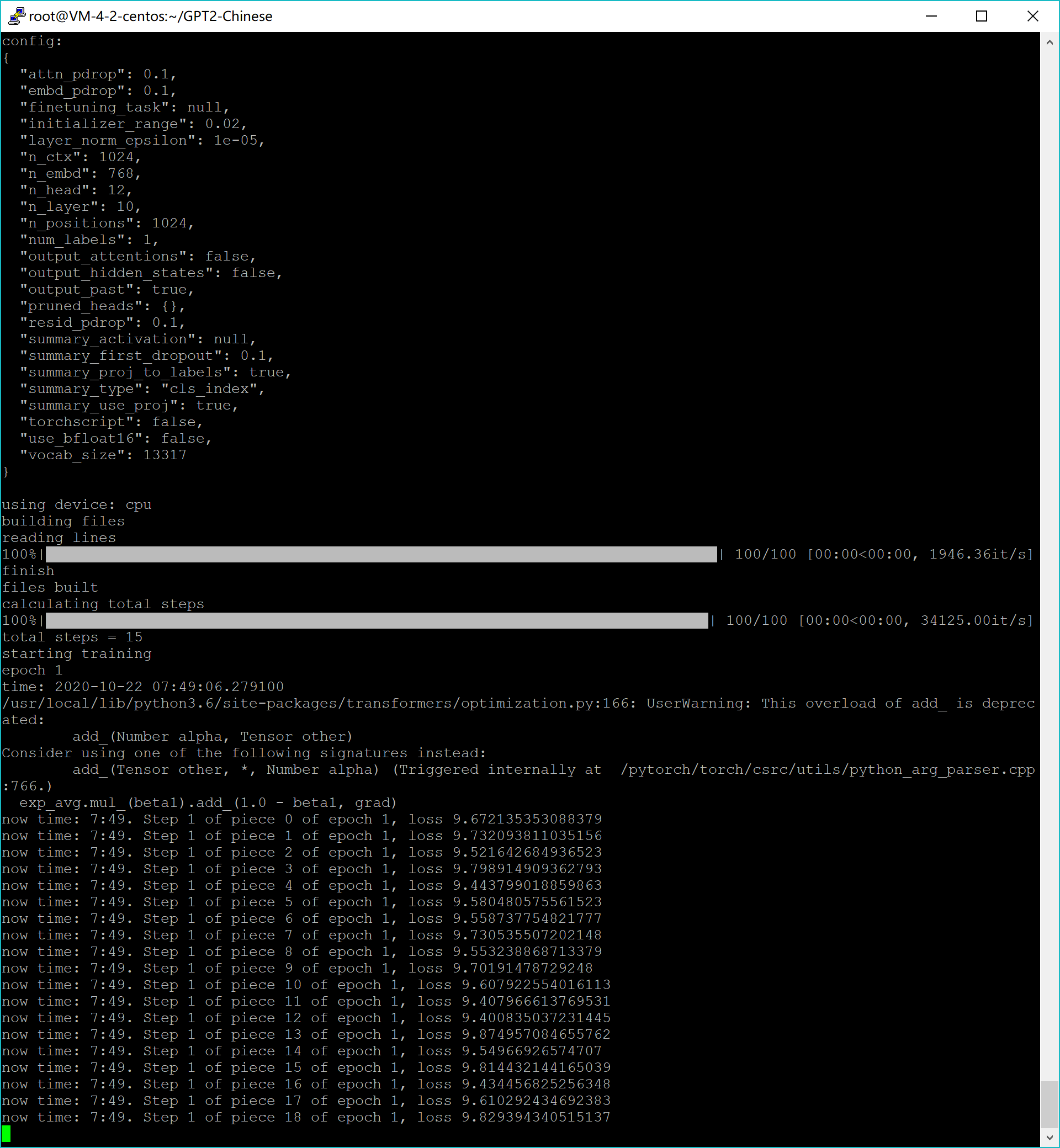
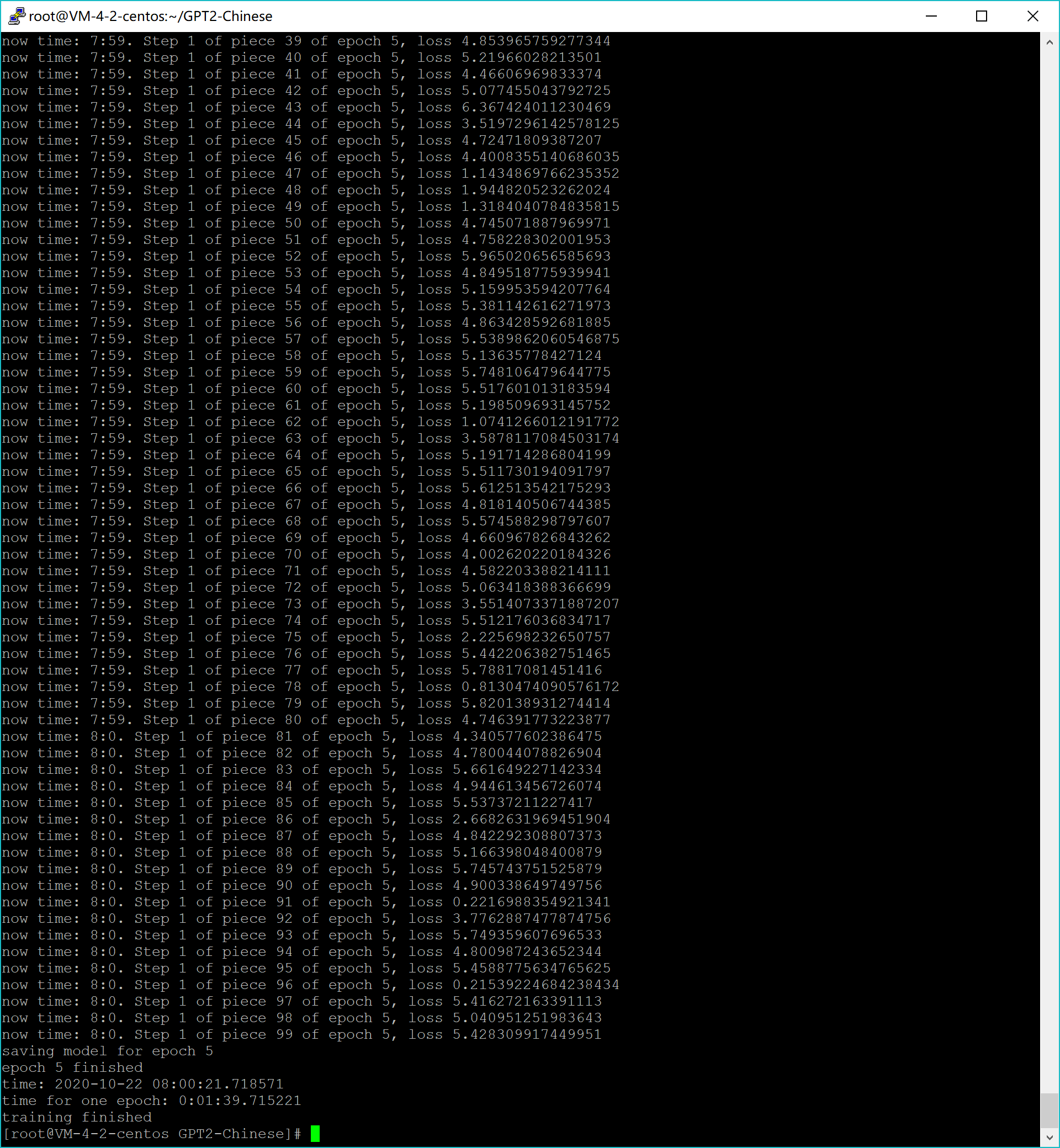
模型训练
python train_single.py --raw
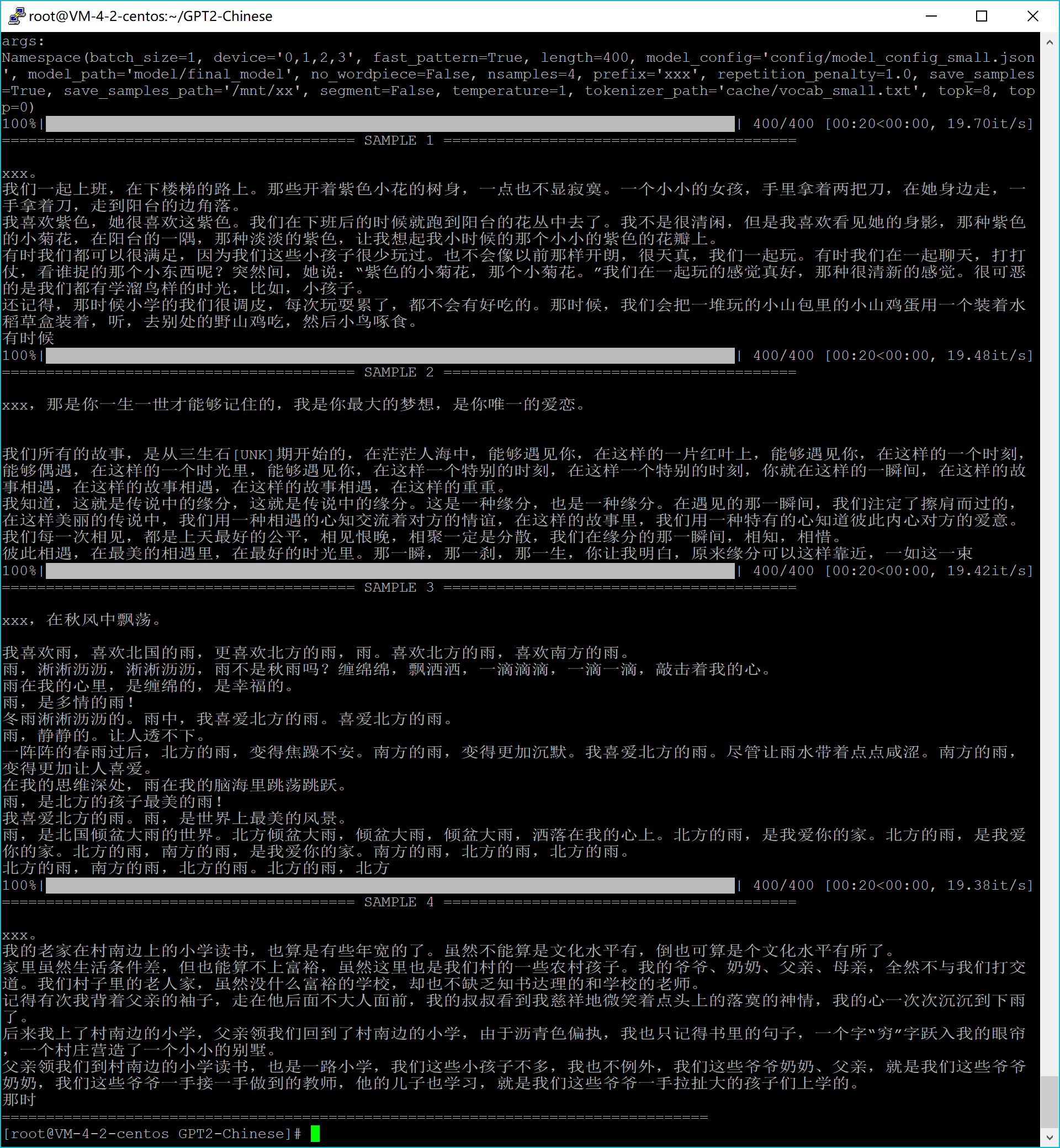
文本生成
python ./generate.py --length=400 --nsamples=4 --prefix=xxx --fast_pattern --save_samples --save_samples_path=/mnt/xx
参数说明
--length:参数为生成文本的长度。
--prefix:生成文章的开头。
--fast_pattern:如果生成的length参数比较小,速度基本无差别,默认不采用fast_pattern方式。
--save_samples:默认将输出样本直接打印到控制台,传递此参数,将保存在根目录下的samples.txt。
--save_samples_path:可自行指定保存的目录,默认可递归创建多级目录,不可以传递文件名称,文件名称默认为samples.txt。结果
- 这里model使用的是hughqiu训练生成模型,感谢分享。
Others
可能需要修改的地方
在train.py中:
#lines = json.load(f)
lines = f.readlines()
#full_tokenizer.max_len = 999999其他类似开源项目
- https://github.com/hughqiu/GPT2-Chinese
- https://github.com/jianyq/Tong-Music
- https://github.com/GaoPeng97/transformer-xl-chinese
- https://github.com/yangjianxin1/GPT2-chitchat
版权属于:moluuser
本文链接:https://archive.moluuser.com/archives/74/
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。


报RuntimeError: CUDA error: device-side assert triggered
怎么解决
你好,我遇到ValueError: too many dimensions 'str'的问题。我想问你是否遇过这个问题?如果遇到过的话能否知道你是怎么解决的?
我遇到了一个process finished with exit code 139 (interrupted by signal l1:SIGSEGV)的问题。请问您遇到过吗,还有您内存多大啊
在CentOS下运行的,内存只有1G-2G左右吧,语料大的话确实会有问题。当时我只是跑一下流程。
python train_single.py --raw大佬,你估计要跑这个代码需要多长时间。我跑这个的时候出现了点问题。FileNotFoundError:【Errno 2】 No such file or directory:'model/model_epocha'。你遇到过吗?谢谢
老哥,你这个生成文本的模型还有吗
模型我用的项目README里面其他人分享的呀,不是自己训练的,训练时间太长了。
可否发一份你的train.json文件啊 我想看看格式
我的邮箱371799296@qq.com 多谢
如果使用train_single.py的话,那train.json可以只是普通的纯文本文件。