
引言
随着移动通信技术的快速发展,网络视频和直播成为信息传播的主要媒介,弹幕技术应运而生。通过弹幕,观看者可以在观看视频的同时发表自己的评论,并将以字幕的形式在当前时间点显示,极大增强了观看者之间的互动性。弹幕包含多维度的属性,文本内容丰富,对其的分析将能有效指导视频平台和内容创作者的生产实践。先前的研究主要针对传统文本,如何利用自然语言处理和可视化技术挖掘海量弹幕中的有效信息,仍存在较大的研究空间。
针对弹幕的多维度属性,本文设计合适的视觉编码利用折线图、文本云、散点图等图形对弹幕的时间、类型、文本等属性进行可视分析。依据可视化结果可以快速发现视频的高光时刻及视频的情节走向。大幅提高了观看者的信息获取效率。
针对弹幕蕴含的情感信息,本文基于Word2vec模型将弹幕文本向量化,采用热图直观的比较不同文本之间的情感差异。使用支持向量机拟合模型,预测弹幕的情感倾向。通过主题河流图将预测结果可视化展示,追踪视频随时间线的情感走向。
本文同时研究了如何将传统的聚类算法应用于弹幕类型数据,结合降维和关键词提取技术,分别使用K均值、LDA主题模型、DBSCAN算法对弹幕文本进行聚类分析。利用可视化技术实现不同聚类的流图展示和聚类效果的评价,准确地提取了视频中的关键信息。
弹幕数据获取与处理
数据获取
近年来,弹幕功能被广泛应用在国内视频平台,例如bilibili、腾讯视频、爱奇艺视频、优酷视频等。弹幕的出现使得视频充满了趣味性,极大地增强了观看者的观影体验和沉浸感。本文选取bilibili作为数据的获取来源,使用Python设计网络爬虫获取视频中的弹幕数据。
在bilibili平台中使用BV号作为稿件的标识,BV号是一段由数字和大小写字母组成的字符串,每个稿件有唯一的BV号与之对应。为了获取单个视频的弹幕数据,需要先得到视频对应的CID属性。
通过构造http://api.bilibili.com/x/player/pagelist?bvid={bvid}形式的请求地址,可以得到如图所示的JSON格式的返回结果,其中包括视频的CID、总时长等属性。

再次构造http://comment.bilibili.com/{cid}.xml形式的请求地址,即可成功获取到如图所示的XML格式的视频弹幕数据。

如上所述,本文通过构造HTTP请求,调用bilibili官方提供的公开接口的方法来获取弹幕数据。在Python中,本文使用Requests库完成上述过程,Requests库基于urllib开发,允许使用者发送原始的HTTP/1.1请求,处理URL资源。
字段分析
| 字段值 | 解释 | |
|---|---|---|
| 69.60700 | 弹幕在视频中出现的时间点(单位:秒) | |
| 1 | 弹幕类型(1-3:滚动弹幕;4:底端弹幕;5:顶端弹幕) | |
| 25 | 弹幕的字体大小 | |
| 16777215 | 弹幕颜色(16进制RGB颜色值转为10进制) | |
| 1618357363 | 发送弹幕的时间戳(Unix时间戳) | |
| 0 | 弹幕池 | |
| c192cf26 | 弹幕发送者的UID(UID通过CRC32校验后转为16进制) | |
| 47823028768735237 | rowID(用于标记顺序和历史弹幕功能) | |
| 好治愈 | 弹幕文本内容 | |
弹幕除了文本维度外还有上述丰富的属性。得到上述所示的弹幕字段释义后,即可以有针对性的对弹幕进行统计和可视分析。本文后续对弹幕的研究将主要面向时间点和内容属性。
弹幕文本清洗
视频中的弹幕文本与传统的中文语句有较大的差异。根据bilibili公司的最新财报显示,bilibili平台的用户平均年龄为21周岁,可见大部分弹幕发送者为青少年群体,发表评论不再局限于传统的中文语法,网络用语使用频繁。如图所示,弹幕中常常出现颜表情、外国语、特殊符号等非中文字符,这些字符的出现大大增加了弹幕文本的分析难度。由于本文主要针对中文弹幕进行可视分析,在多数视频中特殊字符出现的频率较低,故在分析前使用正则表达式对弹幕文本中的非中文字符进行去除操作。

弹幕文本分词
分词是指将连续字符组成的语句,按照语义划分成独立词语的过程。在英文语句中,单词是以空格为分隔符,但在中文语句中没有形式上的分隔符。根据中文的结构特点,可以将分词算法分为基于规则、统计、理解的分词方法。
基于规则的分词方法按照一定的规则,例如正向最大匹配、反向最大匹配、长词优先等规则,将待分析的中文文本与中文词条字段进行匹配。该方法处理速度较快,但无法处理歧义、字典中未收录的词语。基于统计的分词方法的理论依据是常用的词语是高频的汉字组合,同一种组合出现的频率越高,构成词语的概率越大。基于理解的分词方法较为复杂,利用计算机对语句内涵进行解析,完成分词操作。
本文对弹幕文本的分词使用Python中开源的分词工具包Jieba。Jieba分词工具的新词模式基于Viterbi算法,可以对字典中未收录的词语进行识别。精确模式将语句最精确地切开,全模式将语句中所有的词语全部扫描,搜索引擎模式针对长词再次切分,有效提高了召回率。借助于上述模式和自定义字典,对于弹幕的分词结果如图所示。

去除弹幕文本停用词
在弹幕文本中常常出现超高频的常用词,它们几乎不携带有效信息或有较大歧义,分析价值较低。例如虚词“的”、“只”、“从”等。同时,根据不同语境,停用词的选取也有较大的差异。在对弹幕文本进行分析前,需要将其去除以增强分析结果的准确性,同时提高算法效率。常用的去除停用词方法是使用停用词表,即将语料中的元素人工筛选,将停用词整理归纳到字典。本文使用哈尔滨工业大学停用词表,其中包括特殊符号、介词、连词等在内的停用词记录。如图所示为去除停用词后提取的关键词列表。

词语向量化
计算机无法直接解析文本的内涵,故对弹幕文本进行情感和聚类分析前需要对其进行向量化。文本向量化即将文字信息数值化,把人类使用的语言转化为计算机可识别的格式。
弹幕属性可视化
弹幕发送量分析
观看者可以在视频的任意时间点发送弹幕,发送时机和视频情节往往有直接关系。故视频中弹幕发送量高的时间段通常是视频的高光时刻。以BVID为BV1pU4y1h78f的视频为例,绘制如图所示的折线图,其中横坐标为视频时间线,纵坐标为相应时间节点的弹幕数量。从可视化的图形中可以看出,弹幕发送量的峰值出现在800秒到900秒区间内。可以推测,此时间区间的视频内容更容易触发观看者共鸣,观看者发送弹幕的动机较高,其中有可能包含视频的关键信息。为了验证上述推测,通过浏览视频发现,在该时间区间内视频创作者发表了与视频标题有关的见解,进而证明了推测的正确性。在150秒、650秒、750秒时弹幕发送量较低,在此时间点附近更可能是视频的情节低谷期。

在视频中,弹幕通常分为滚动弹幕、顶部弹幕和底部弹幕。结合弹幕类型、弹幕长度、弹幕发送量绘制如图所示散点图。横坐标为视频时间线,纵坐标为弹幕文本的长度。散点中的数字为弹幕的频次,红色代表滚动弹幕,浅蓝色为底部弹幕,黄色为顶部弹幕。从图中的散点密集程度可以直观看出在视频800秒后一段时间内弹幕发送量较为密集,同时顶部弹幕发送量高于平均水平,在400秒和650秒左右的长弹幕发送量较高。浏览视频可以发现在上述时间点附近创作者在发表社会事件的评论,该时间片段为新闻评论类视频的高光时刻。

通过弹幕发送量的可视分析结果,观看者可以快速直观地找到视频中关键内容的时间点,从而可以有选择性的观看视频内容,短时间内了解视频的特点和精髓,提高了信息的获取效率。
弹幕文本分析
一般地,观看者发送的弹幕文本与当前视频内容有一定关联,通过提取弹幕中的关键词,试图找到视频的关键信息。根据关键词生成文本云如图所示,关键词出现的频率反映到文本云中的视觉编码即字号大小。词频较高的关键词有“电信”、“移动”、“铁通”、“阿里”、“腾讯”、“垄断”、“初装费”,可以推测出该视频在讨论互联网及电信公司的垄断问题。

为了更详细展示视频中的关键信息,通过对时间切分,将其均匀切分为九段,分别对其中的关键词生成文本云如图所示,图中红色箭头指向为时间线方向。观看者可以以时间线的顺序快速预览视频内容,例如视频的前2/9的时间在讲述电话的安装,在第3/9的时间段内讨论电信公司,中间的时间段讨论互联网公司的垄断问题,在第8/9的时间段内讨论共享单车。

观看者无需浏览视频,通过阅读相应的文本云即可获取到视频中的有效信息。阅读对视频切分后的文本云,观看者可以对视频的局部内容进行了解,选取感兴趣的片段进行浏览,降低了观看者筛选视频的时间成本。
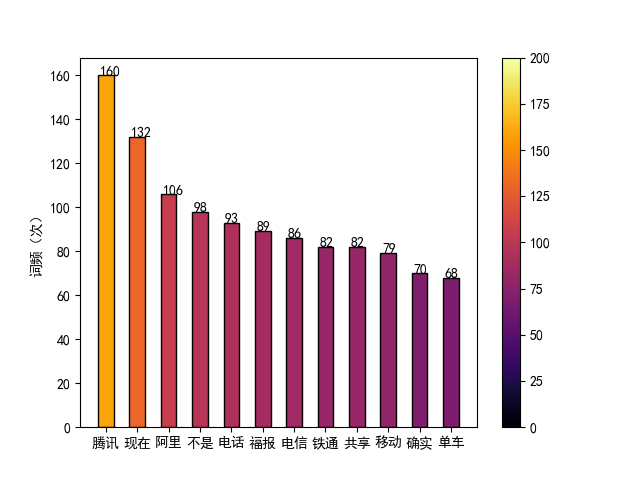
弹幕文本分词后,对关键词词频进行可视化得到上图。在图中,关键词的词频由左到右递减,观看者通过预览该图可以了解到视频的主要内容。与此同时,图中词频较高的关键词反映了观看者评论的舆论走向。以此为依据,运营人员可以制定相关推广策略以增强视频的传播力。
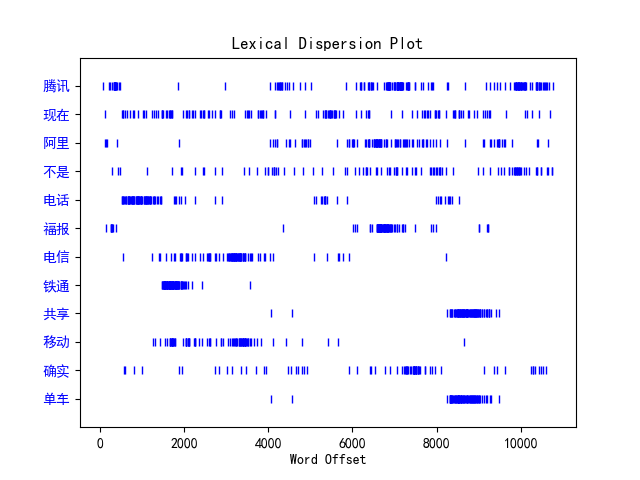
为了体现弹幕的时间属性,将弹幕文本分词后,选取词频较高的关键词,按视频的时间顺序进行排序,绘制词汇分散图如图所示,图中纵坐标表示不同的关键词,横坐标表示累加的关键词字数,即关键词字数增长的方向与视频中时间轴正方向一致,蓝色竖线的密度表示该词在视频弹幕文本中被提及的频次和时间点。通过该图可以较好了解在某段时间中视频叙述的主要内容。
弹幕其他属性分析
在浏览视频的过程中,观看者可以发送多条弹幕。在爬取到的弹幕数据中有一列字段为发送者标识,通过对该字段的分析可以得到下图。在图中,n代表发送弹幕的条数,可以发现,80.59%的观看者倾向于发送单条弹幕,0.2%的观看者发送的弹幕超过10条,平均弹幕发送量为1.34条。分析可以得出超过90%的观看者发送1或2条弹幕的结论。
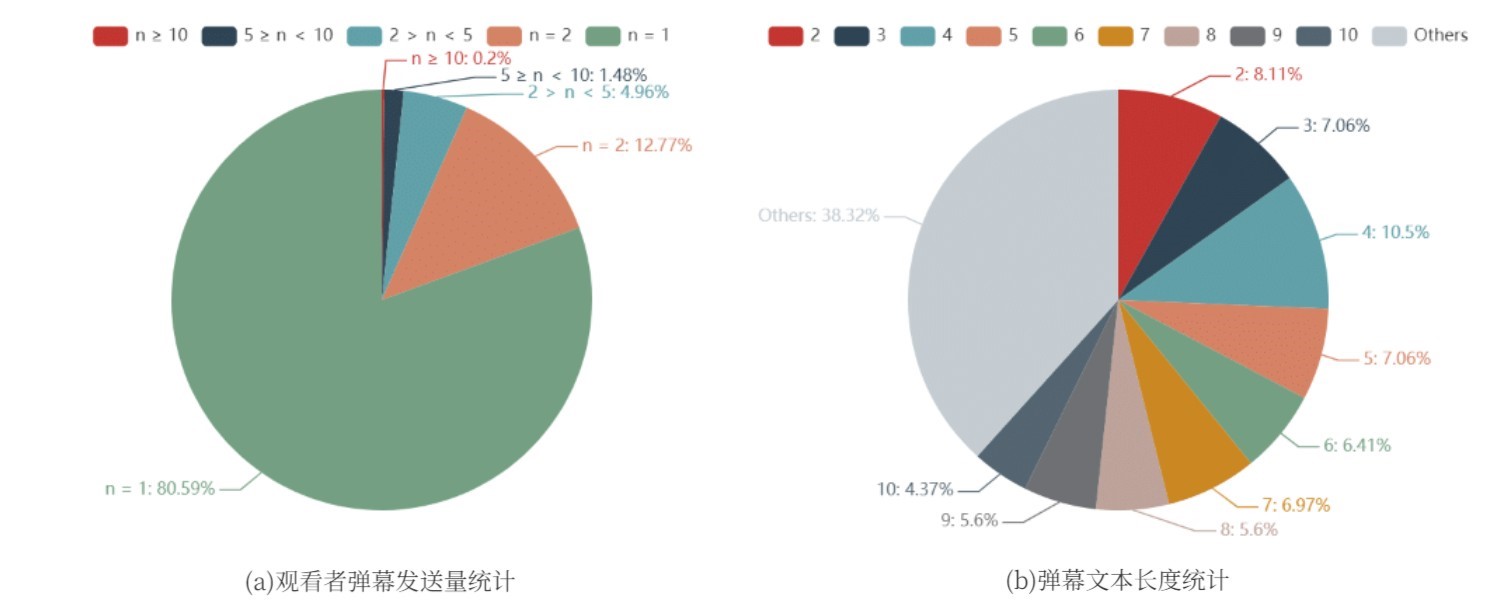
分析观看者发送弹幕的文本长度如图所示。可以发现,文本长度占比最高的是四个字符,占10.5%,较多用户选择发送短弹幕进行互动。弹幕的平均文本长度为10.3313个字符。此项数据可以帮助平台优化弹幕滚动速度,提升用户体验。
分析弹幕类型发现,95.4%的弹幕为普通滚动弹幕,4.3%为顶部弹幕,0.3%为底部弹幕。弹幕颜色的分析结果显示,92.8%的弹幕为默认的黑色,其次最高出现的颜色为红色,出现频率为2.7%。以上结果证明绝大多数观看者在发送弹幕时,偏向于不更改弹幕的默认选项。
弹幕情感可视化
情感是人与客观事物相互作用,在大脑中产生的感受。弹幕文本包含观看者对于视频当前时间点内容的情感倾向,通过对视频中海量弹幕的情感分析,可以跟踪视频随时间变化的情感走向。文本的情感分析根据对情感倾向的细分程度可以分为细粒度和粗粒度情感分析。其中粗粒度情感分析一般将情感划分为正向和反向。细粒度分析则对情感的划分更为精细,实现起来也更加困难。本文针对弹幕文本进行粗粒度情感分析,并将分析结果可视化展示。
情感分析方法
情感分析即通过算法判断文本的情感偏向,达到分析出文本作者的主观情绪的目的。最传统的情感分析方法是基于词典进行的情感分析,首先构建情感词典,其中包括所有有关的正向词和负向词并对其进行评分,同时前向搜索词语以发现否定词。通过遍历文本中所有的词语,将词语评分并求和计算情感得分。该方法的优点是实现简单,但无法处理新词、特殊词语且忽略了文本中上下文包含的信息。
随后有学者提出基于词袋模型的情感分析方法,该方法将文本的情感分析问题转化为文本分类,该模型将文本转化为N维向量,N为全部文本的词语总数,向量中每个维度的值代表对应词的出现频率。虽然预测效果得到改进,但该模型仍然忽略上下文信息且效率较低。
针对弹幕类型的短文本,本章将使用基于Word2vec词向量的情感分析方法。该模型可以获取到词语之间的关联信息,通过训练,将对文本的处理转化为词向量的运算,有效解决了上述方法的不足。
可视化方法
数据可视化将高维且冗长的数据转化为更为直观的图形,设计合适的视觉编码对原始数据中隐含的信息进行展示。弹幕文本隐含发送者的主观情感信息,但其文本量大,信息获取困难。利用上文建立的情感评价模型,对视频中的弹幕逐条进行分析,将分析结果以图形的方式展现,运营平台即可快速发现视频的正向和负向信息,实现视频内容的实时审查和平台的舆情监测。
针对词向量分析,本文以热图的形式对词语情绪倾向进行可视分析。热图中横坐标为向量的维数,每个色块代表当前维度的值。通过对比不同词语生成热图的相似度,即可直观比较词语内涵的差别。针对语句情感分析同样适用于该方法。利用模型,对视频中全部的弹幕文本情感倾向后,本文使用ThemeRiver对视频中弹幕文本的情感倾向以时间线的顺序进行展示,意为主题河流图。图形中,横坐标为时间,利用不同颜色的线条代表正向和负向的情感倾向,纵坐标为弹幕发送量,线条的宽度即可表现当前节点的情感强度,视频整体的情感倾向走势得以完整展现。
弹幕向量化
首先,构造有情感标注的文本作为模型训练的数据集。对文本进行分词操作,不再对训练集中的文本进行去除停用词等预处理步骤,保留文本的原始信息。随后按照比例生成训练集和测试集。由于弹幕文本的长度各不相同且其一般为短文本,故使用词向量的平均值作为分类算法的输入长度,使用Word2vec将词语转为向量表示。为了评价单条弹幕文本的情感倾向,求取弹幕文本中所有词语的词向量平均值作为单条弹幕文本的向量表示。
在将所有弹幕文本向量表示后,将弹幕文本向量化后的数据输入支持向量机进行训练,构造文本情感分类模型。
预测模型
本文使用RBF为其核函数,通过支持向量机算法构建模型,预测弹幕文本的情感倾向为正向或负向。
实验中使用互联网公开的新浪微博(https://weibo.com)评论数据集作为模型的训练集,该数据集包含119988条已经标注情感倾向的评论记录,总大小为18.7MB,样本情况如下表所示。其中,情感标记为“1”的评论为正向,标记为“0”的评论为负向。弹幕数据选取bilibili视频平台中BVID为BV1GK411T77V的视频为数据来源,每行原始弹幕数据包含时间、类型、字号、颜色、发送者标识、文本等字段。
| 情感标记 | 评论 |
|---|---|
| 1 | 右边的,说的太对了! |
| 1 | 真心舒服开怀爱你 |
| 1 | 期待[哈哈] |
| 0 | 好累啊!只想回家,躺在床上,把自己放平,呆着。[抓狂] |
| 0 | 累死人啦... |
本实验使用上述语料数据对模型进行训练。特征向量维度设置为300、min_count设置为10,min_count代表词频小于10的词语不再纳入模型的建立、epoch设置为10,即在训练中文本的轮数为10。
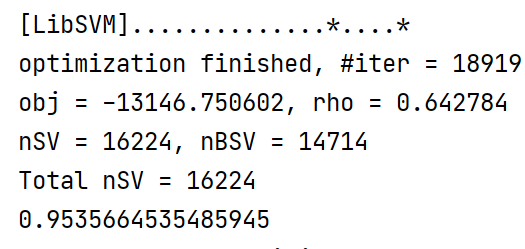
最终得到如图所示的模型结果。可以发现,在迭代18919次后模型的准确率约为95%。
使用验证集对模型进行评估,结果如图所示。可以发现,该模型的精确率、召回率、F1值均在95%附近,预测准确率较高。
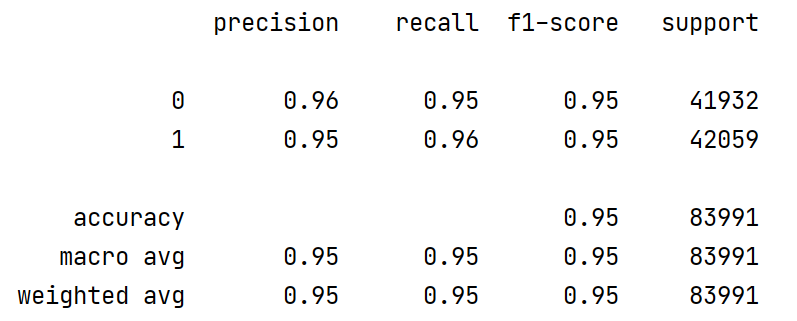
使用该模型对弹幕文本进行预测,得到结果如图所示,图中最后一个字段为模型预测结果。观察输出的结果中弹幕文本和预测结果字段,模型预测较为准确。

结果可视化
将弹幕文本使用Word2vec模型转化为向量。例如,针对语句“梦想就在前方去做自己想做的事情吧你会成功的可能这就是梦想吧”,分词后得到“['梦想', '就', '在', '前方', '去', '做', '自己', '想', '做', '的', '事情', '吧', '你', '会', '成功', '的', '可能', '这', '就是', '梦想', '吧']”。对分词结果转化为向量如图所示。

使用该文本向量数据生成热图如图所示,图形中蕴含文本的情感信息,相近情感文本的可视化结果相似度较高。词向量的可视化使得对语句相似度的观察更为直观。

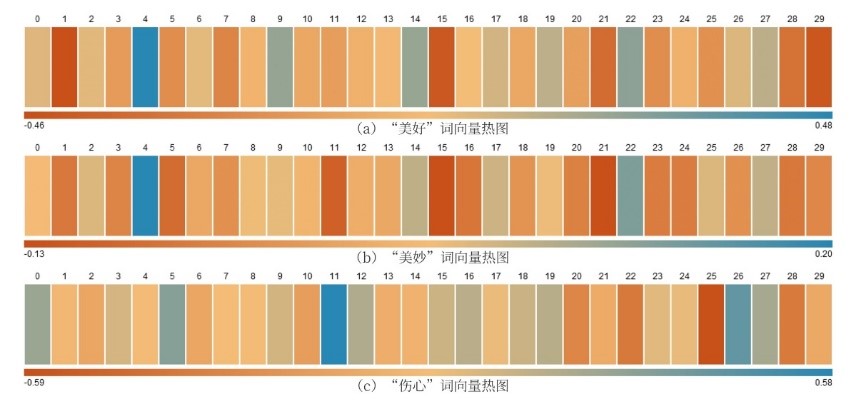
选取“美好”、“美妙”、“伤心”词语输入训练完成的模型,将输出的向量以10为间隔采样后计算平均值,以转化为30维向量,对其进行可视化得到下图。“美好”与“美妙”词语的情感相近,故观察图形即可发现二者的热图相似度较高,“伤心”词语与之情感相反,在图形中表现为颜色差异明显。
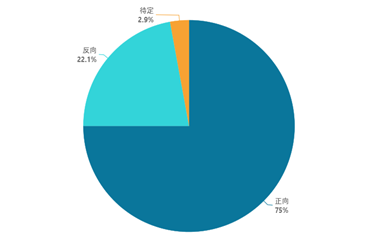
根据实验结果数据,首先绘制下图,可以发现,在视频中正向情感倾向的弹幕发送量远大于负向情感倾向的弹幕。
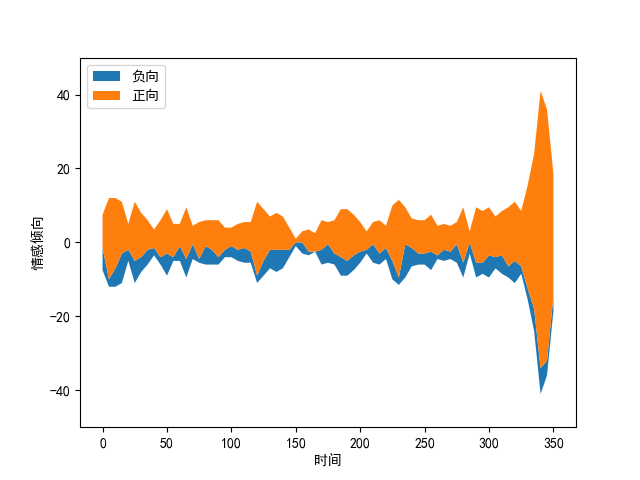
随后,绘制出视频中弹幕的情感倾向随时间变化的主题河流图,如下图所示。通过线条宽度可以发现,在视频即将结束的时间区间内弹幕发送量激增,说明在该时间区间内的视频内容更能引起观看者的情感波动。通过情感倾向分析的可视化结果,可以对视频中弹幕发送者的情绪有较清晰的了解,进而分析视频随时间线的情节走向。
弹幕聚类分析
中文文本聚类是采用恰当的算法,将文本划分为若干簇,同一簇中的文本有相近的语言内涵。文本的聚类是一种无监督的机器学习算法,致力于从海量文本中挖掘出有效的信息。对于基于机器学习的文本聚类一般包括下述流程:文本预处理、向量化、设计聚类算法、聚类结果分析。其中文本的预处理和向量化前文已有详尽说明。文本的聚类算法一般分为基于划分、密度、层次、模糊、网格和模型的方法,不同的聚类算法针对特定文本通常有不同的聚类效果和结果可视化程度。
在基于划分的聚类方法中,首先指定划分数目K的数值,通过迭代算法使得样本点在不同簇之间移动,最终找到最优的聚类效果。其中常见的有K均值聚类方法,本章将对其进行详细阐述。在基于密度的聚类方法中,首先指定区域的半径,当指定区域的样本点密度超过一定的阈值时就聚为一簇。基于层次的聚类方法首先将每个样本点视为单独的一簇,循环合并相近的样本点或簇,最终将所有簇归为一簇即完成聚类操作。基于模糊的聚类方法使用模糊数学的方法进行聚类分析,对于符合正态分布的样本点效果优异。基于网格的聚类算法使用样本点构成网格结构,聚类即将网格进行合并的过程,处理速度较快。基于模型的聚类算法假定每一簇为一个模型,寻求与该模型达到最优拟合的样本点。
本章试图改进和使用不同的算法对弹幕文本进行聚类分析,挖掘视频弹幕中的隐含信息,最终将结果使用可视化的手段进行展示。
数据集
选取bilibili视频平台中BVID为BV1GK411T77V的视频作为弹幕数据来源。
基于K均值的弹幕聚类
基于上述环境和语料,首先对弹幕文本进行分词、向量化、降维操作。使用K均值聚类算法,选取最优K值。具体方法为分别计算不同K值下的误差平方和和轮廓系数如图所示。
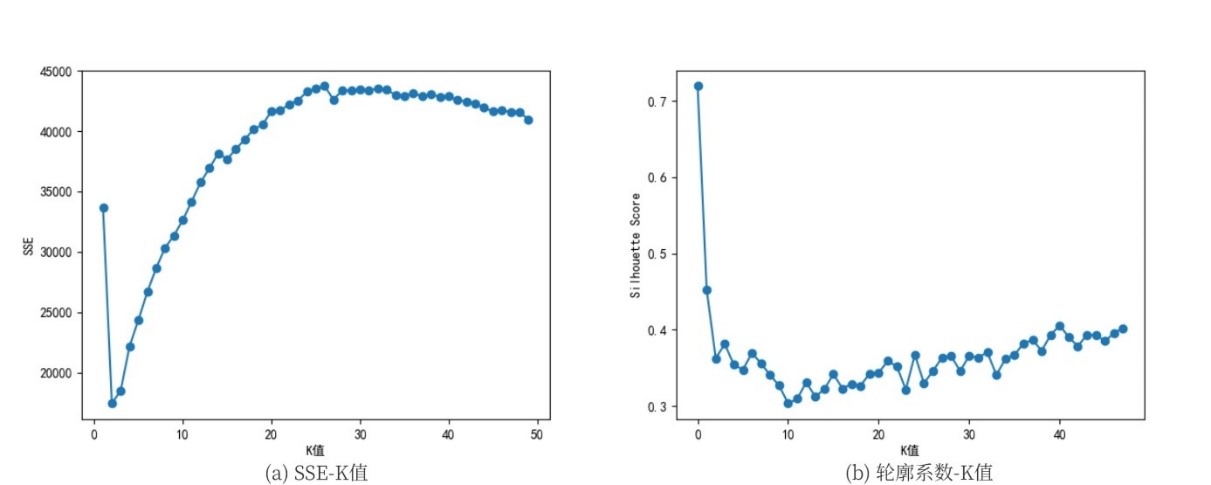
综合考虑评价标准,最终选取K等于3,此时聚类效果和聚类轮廓宽度如下图。
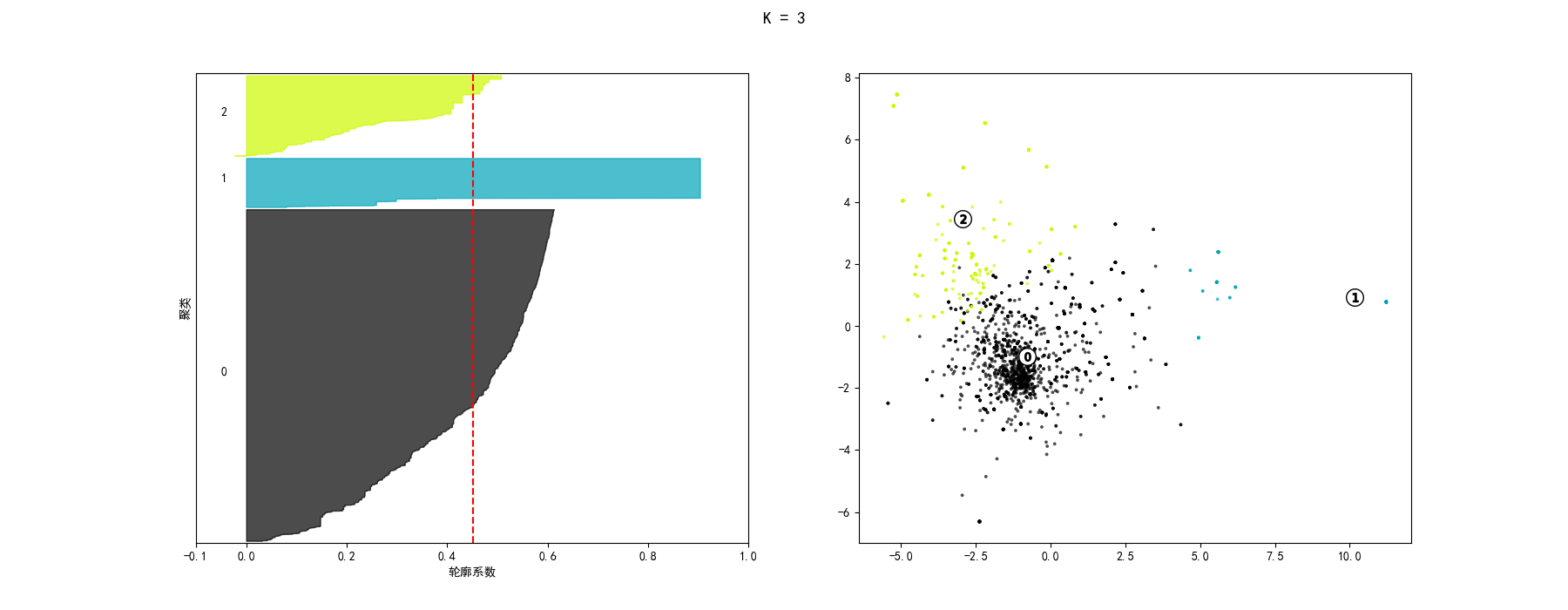
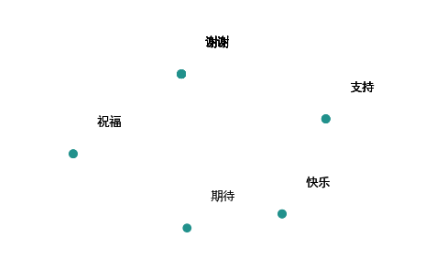
将弹幕文本词语渲染到聚类结果图中,选取局部视图如图,可以发现图中词语含义相近,其内涵均为赞赏。
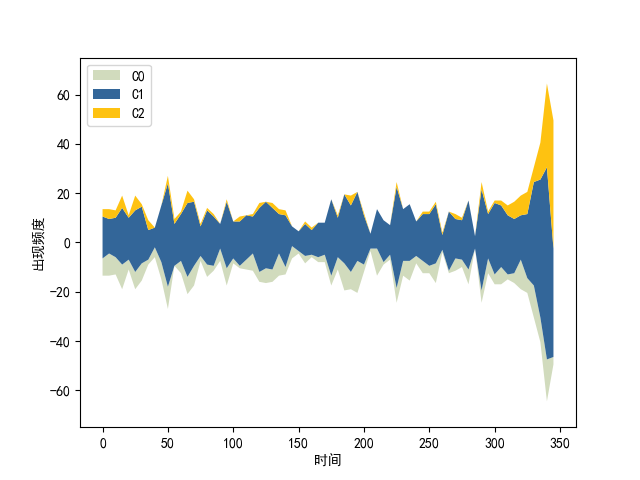
根据聚类的结果,绘制如图所示的主题河流图,图中每种颜色线条代表一簇聚类结果。横坐标为视频的时间线。可以发现,图中第2簇聚类在视频结尾处频率激增,在视频其他部分出现频度近似为零,查看该簇聚类内容发现,其中包含词语“['加油', '努力', '谢谢', '支持', '祝福', '辛苦', '快乐', '感谢', '期待']”,在视频结尾由于视频创作者的观点表达,观看者对视频创作者赞赏的情绪高涨。第1簇聚类由于包含词语过多,故其出现频度在视频的全部时间段都较高,第0簇聚类词语大多为动词,例如“发现”、“觉得”等,参考价值不高。
基于LDA主题模型的弹幕聚类
根据上述数据,对弹幕文本进行基于主题模型的聚类。依据Coherence score(u_mass)选取最优主题数。绘制图,观察图中最大值,选取主题数为9。将结果进行可视化得到图。

选取主题模型中的两簇,查看其包含词语如图所示。图中红色柱状图表示该词在当前主题中占的权重,蓝色表示该词在整个视频中占的权重。可以发现视频弹幕有较大部分是为视频创作者“加油”,同时进行鼓励。
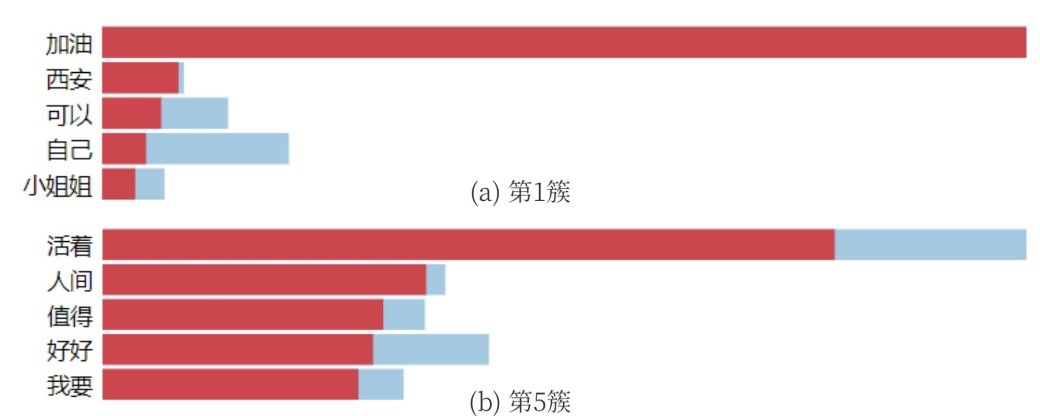
基于DBSCAN的弹幕聚类
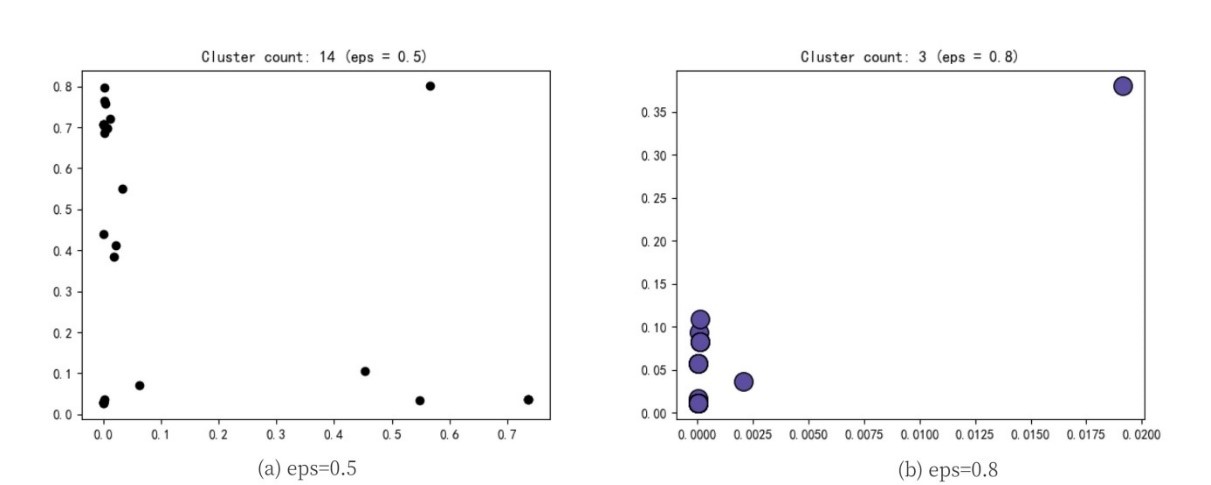
根据上述数据,使用DBSCAN算法对弹幕文本进行聚类,选取eps为0.5与0.8进行聚类的效果图如图所示。eps表示聚类过程中的距离阈值,当该值过大时,类别数将减少。图中聚类数为14,噪点数为35。图中聚类数为3,噪点数为0。由于输入弹幕样本过少,故聚类效果图过于稀疏。通过观察比较发现eps为0.8时聚类效果较好,故后续基于该聚类结果进行分析。
输出聚类后的三簇弹幕文本如图所示。观察聚类结果,发现第一簇多为对视频创作者的正面评价,第二簇观点多为负面,第三簇弹幕文本多出现“西安”,观看视频后发现在视频中视频创作者的旅行始发站为西安站。

结论
本文基于机器学习算法,对视频弹幕进行研究,以bilibili网站弹幕数据为例,对弹幕进行可视分析。综合国内外已有的研究成果,在现有的研究基础上设计针对弹幕类型数据的情感分析和聚类算法,对于结果进行评价。本文的研究内容如下:
设计网络爬虫获取弹幕数据,分析弹幕数据中各字段的含义。之后对弹幕文本进行清洗,去除与研究主题不相关的元素。其次对语句进行分词,去除停用词操作以及使用Word2vec模型对词语进行向量化,将文本转化为计算机可以识别的向量信息。为了提高查询和存储效率,将获取到的弹幕数据使用数据库进行存储。
针对单个视频中的弹幕,本文使用折线图和散点图将弹幕的发送量、弹幕文本长度和弹幕类型结合弹幕的时间属性进行可视分析。依据分析结果,观看者可以快速找到视频的高光时刻,有针对性浏览视频内容。对于弹幕文本,本文采用对全部弹幕生成文本云和将视频的时间分段生成文本云的策略,可视化结果可以展现出视频随时间推移的叙述内容变化,结合直方图和关键词分散图,视频中的关键信息和其出现时间得以完整展现。本文同时针对弹幕的发送者、类型、颜色进行逐一统计分析,得出绝大多数观看者一般不改变弹幕选项的结论。
本文对弹幕文本的情感倾向进行可视分析。基于Word2vec模型将单条弹幕文本向量化,采用热图对向量化后的词语和弹幕文本进行可视化,通过情感热图可以直观比较不同文本之间的情感差异。使用支持向量机对向量化后的文本进行拟合,预测单条弹幕文本的情感倾向。在得出弹幕的情感倾向结论后,使用主题河流图追踪视频中弹幕情感倾向的变化,进而推测出视频随时间线的情节走向。
在现有的聚类算法基础上,本文探究了对弹幕类型数据的聚类方法。分别使用K均值、LDA主题模型、DBSCAN算法对弹幕文本进行聚类分析,选取恰当的评价标准衡量聚类效果的优劣。最终将弹幕的聚类结果进行可视化展示,同时结合视频内容解释其含义。
参考文献
[1] 中国互联网络信息中心(CNNIC).第47次中国互联网络发展现状统计报告[R].2021年2月4日.
[2] Fastdata极数.2020年中国互联网发展趋势报告[R].2020年12月4日.
[3] 彭聃龄. 普通心理学[M]. 北京师范大学出版社,2012
[4] 周志华. 机器学习[M]. 清华大学出版社,2016
[5] 吴启纲. 中文文本聚类算法的研究与实现[D]. 西安电子科技大学, 2010.
[6] 磯貝佳輝, 齊藤義仰, 村山優子. 視聴者コメントを用いた動画検索支援のためのダイジェスト動画作成アルゴリズムの検討[J]. 第 73 回全国大会講演論文集, 2011, 2011(1): 347-348.
[7] 郑飏飏, 徐健, 肖卓. 情感分析及可视化方法在网络视频弹幕数据分析中的应用[J]. 数据分析与知识发现, 2016, 31(11): 82-90.
[8] 段炼. 面向弹幕文本的情感分析研究[D]. 重庆邮电大学, 2019.
[9] Bai Q, Hu Q V, Ge L, et al. Stories that big danmaku data can tell as a new media[J]. IEEE Access, 2019, 7: 53509-53519.
[10] Chen Z, Tang Y, Zhang Z, et al. Sentiment-aware short text classification based on convolutional neural network and attention[C]//2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI). IEEE, 2019: 1172-1179.
[11] 刘李姣. 面向视频弹幕的文本情感分析研究[D]. 兰州交通大学 2020
[12] Li Z, Li R, Jin G. Sentiment analysis of danmaku videos based on Naïve Bayes and sentiment dictionary[J]. IEEE Access, 2020, 8: 75073-75084.
[13] Yin F, She Y, Xiong R, et al. A Sentiment Analysis Algorithm of Danmaku Based on Building a Mixed Fine-grained Sentiment Lexicon[C]//Proceedings of the 2020 9th International Conference on Computing and Pattern Recognition. 2020: 424-430.
[14] Wang S, Chen Y, Ming H, et al. Improved Danmaku Emotion Analysis and Its Application Based on Bi-LSTM Model[J]. IEEE Access, 2020, 8: 114123-114134.
[15] 唐家渝,刘知远,孙茂松.文本可视化研究综述[J].计算机辅助设计与图形学学报,2013,25(3):273-285.
[16] 屈华民. 数据可视化5简介[R]. 杭州:浙江大学CAD&CG实验室.2013
[17] 屈华民. 感知与认知7[R]. 杭州:浙江大学CAD&CG实验室.2013
[18] 方晓芬. 数据基础[R]. 杭州:浙江大学CAD&CG实验室.2013
[19] 陈为,沈则潜,陶煜波. 数据可视化[M]. 电子工业出版社, 2019
[20] Havre S, Hetzler E, Whitney P, et al. Themeriver: Visualizing thematic changes in large document collections[J]. IEEE transactions on visualization and computer graphics, 2002, 8(1): 9-20.
[21] Lee B, Riche N H, Karlson A K, et al. Sparkclouds: Visualizing trends in tag clouds[J]. IEEE transactions on visualization and computer graphics, 2010, 16(6): 1182-1189.
[22] Cui W, Liu S, Tan L, et al. Textflow: Towards better understanding of evolving topics in text[J]. IEEE transactions on visualization and computer graphics, 2011, 17(12): 2412-2421.
[23] Wei F, Liu S, Song Y, et al. Tiara: a visual exploratory text analytic system[C]//Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining. 2010: 153-162.
[24] Liu S, Wu Y, Wei E, et al. Storyflow: Tracking the evolution of stories[J]. IEEE Transactions on Visualization and Computer Graphics, 2013, 19(12): 2436-2445.
[25] Viégas F B, Wattenberg M, Dave K. Studying cooperation and conflict between authors with history flow visualizations[C]//Proceedings of the SIGCHI conference on Human factors in computing systems. 2004: 575-582.
[26] Paley W B. Textarc: Showing word frequency and distribution in text[C]//Poster presented at IEEE Symposium on Information Visualization. 2002, 2002.
[27] Keim D A, Oelke D. Literature fingerprinting: A new method for visual literary analysis[C]//2007 IEEE Symposium on Visual Analytics Science and Technology. IEEE, 2007: 115-122.
[28] Wattenberg M, Viégas F B. The word tree, an interactive visual concordance[J]. IEEE transactions on visualization and computer graphics, 2008, 14(6): 1221-1228.
[29] Van Ham F, Wattenberg M, Viégas F B. Mapping text with phrase nets[J]. IEEE transactions on visualization and computer graphics, 2009, 15(6): 1169-1176.
[30] Ong T H, Chen H, Sung W, et al. Newsmap: a knowledge map for online news[J]. Decision Support Systems, 2005, 39(4): 583-597.
[31] 李东霞.弹幕视频网站文献综述[J].福建质量管理,2020,(10):216.
[32] 王佳琪.基于弹幕视频网站的弹幕文化研究[D].山东:山东师范大学,2015.
[33] Bilibili Inc.Annual Report 2020[R]. https://ir.bilibili.com/static-files/98bfad59-0a57-467c-a3f4-e250c3bada4b, 2021.
[34] 刘砚博. 基于深度学习的情感分析研究与应用[D]. 电子科技大学, 2019.
[35] 郑佳. 搜索引擎分类展示技术研究[D]. 哈尔滨工业大学, 2012.
[36] Xiong Y, Chen S, Qin H, et al. Distributed representation and one-hot representation fusion with gated network for clinical semantic textual similarity[J]. BMC medical informatics and decision making, 2020, 20: 1-7.
[37] Bengio Y, Ducharme R, Vincent P, et al. A neural probabilistic language model[J]. The journal of machine learning research, 2003, 3: 1137-1155.
[38] Li C, Lu Y, Wu J, et al. LDA meets Word2Vec: a novel model for academic abstract clustering[C]//Companion proceedings of the the web conference 2018. 2018: 1699-1706.
[39] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.
[40] Kenter T, Borisov A, De Rijke M. Siamese cbow: Optimizing word embeddings for sentence representations[J]. arXiv preprint arXiv:1606.04640, 2016.
[41] 徐永东. 多文档自动文摘关键技术研究[D]. 哈尔滨: 哈尔滨工业大学, 2007.
[42] F. B. Viegas, M. Wattenberg and J. Feinberg, "Participatory Visualization with Wordle," in IEEE Transactions on Visualization and Computer Graphics, 2009, 15(6):1137-1144.
[43] Heimerl F, Lohmann S, Lange S, et al. Word cloud explorer: Text analytics based on word clouds[C]//2014 47th Hawaii International Conference on System Sciences. IEEE, 2014: 1833-1842.
[44] Bai Q, Hu Q, Fang F, et al. Topic detection with Danmaku: A time-sync joint NMF approach[C]//International Conference on Database and Expert Systems Applications. Springer, Cham, 2018: 428-435.
[45] 明弋洋, 刘晓洁. 基于短语级情感分析的不良信息检测方法[J]. 四川大学学报 (自然科学版), 2019, 6.
[46] 邓扬, 张晨曦, 李江峰. 基于弹幕情感分析的视频片段推荐模型[J]. 计算机应用, 2017, 37(4): 1065-1070.
[47] 赵妍妍, 秦兵, 刘挺. 文本情感分析[J]. 软件学报, 2010, 21(8): 1834-1848.
[48] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[J]. arXiv preprint arXiv:1310.4546, 2013.
[49] 梁军, 柴玉梅, 原慧斌, 等. 基于深度学习的微博情感分析[J]. 中文信息学报, 2014, 28(5): 155-161.
[50] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[J]. arXiv preprint arXiv:1310.4546, 2013.
[51] Joachims T. Making large-scale SVM learning practical[R]. Technical report, 1998.
[52] July. 支持向量机通俗导论(理解SVM的三层境界)[DB/OL]. https://blog.csdn.net/v_july_v/article/details/7624837, 2012.6.
[53] 杨开平. 基于语义相似度的中文文本聚类算法研究[D]. 电子科技大学, 2018.
[54] 许君宁. 基于知网语义相似度的中文文本聚类方法研究[D]. 西安电子科技大学, 2010.
[55] MacQueen J. Some methods for classification and analysis of multivariate observations[C]//Proceedings of the fifth Berkeley symposium on mathematical statistics and probability. 1967, 1(14): 281-297.
[56] Dunteman G H. Principal components analysis[M]. Sage, 1989.
[57] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. the Journal of machine Learning research, 2003, 3: 993-1022.
[58] Schubert E, Sander J, Ester M, et al. DBSCAN revisited, revisited: why and how you should (still) use DBSCAN[J]. ACM Transactions on Database Systems (TODS), 2017, 42(3): 1-21.
[59] Joachims T. A Probabilistic Analysis of the Rocchio Algorithm with TFIDF for Text Categorization[R]. Carnegie-mellon univ pittsburgh pa dept of computer science, 1996.
[60] McNamara D S, Boonthum C, Levinstein I B, et al. Evaluating self-explanations in iSTART: Comparing word-based and LSA algorithms[J]. Handbook of latent semantic analysis, 2007: 227-241.
[61] Henri Trenquier. Improving Semantic Quality of Topic Models for Forensic Investigations[D]. University of Amsterdam, 2018.
注:在弹幕聚类方面,作者能力有限,可能不准确或有误,欢迎指正。
版权属于:moluuser
本文链接:https://archive.moluuser.com/archives/93/
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。


这篇文章写得深入浅出,让我这个小白也看懂了!
非常感谢你分享这篇文章,我从中学到了很多新的知识。
鸟叔来串门,通过虫洞穿梭至此,期待回访!
十年之约-虫洞穿梭至此,期待回访!
分析很到位,很详细